Exporting Data from BigQuery to Snowflake, the Easy Way
Learn how to extract data from BigQuery and load it into Snowflake using Sling Cloud or Sling CLI.

A technical data engineer / passionate technologist who loves tackling interesting problems with code, exploration & persistence.
Cloud Data Warehouses
In the past few years, we've seen a rapid growth in the usage of cloud data warehouses (as well as the "warehouse-first" paradigm). Two popular cloud DWH platforms are BigQuery and Snowflake. Check out the chart below to see their evolution over time.
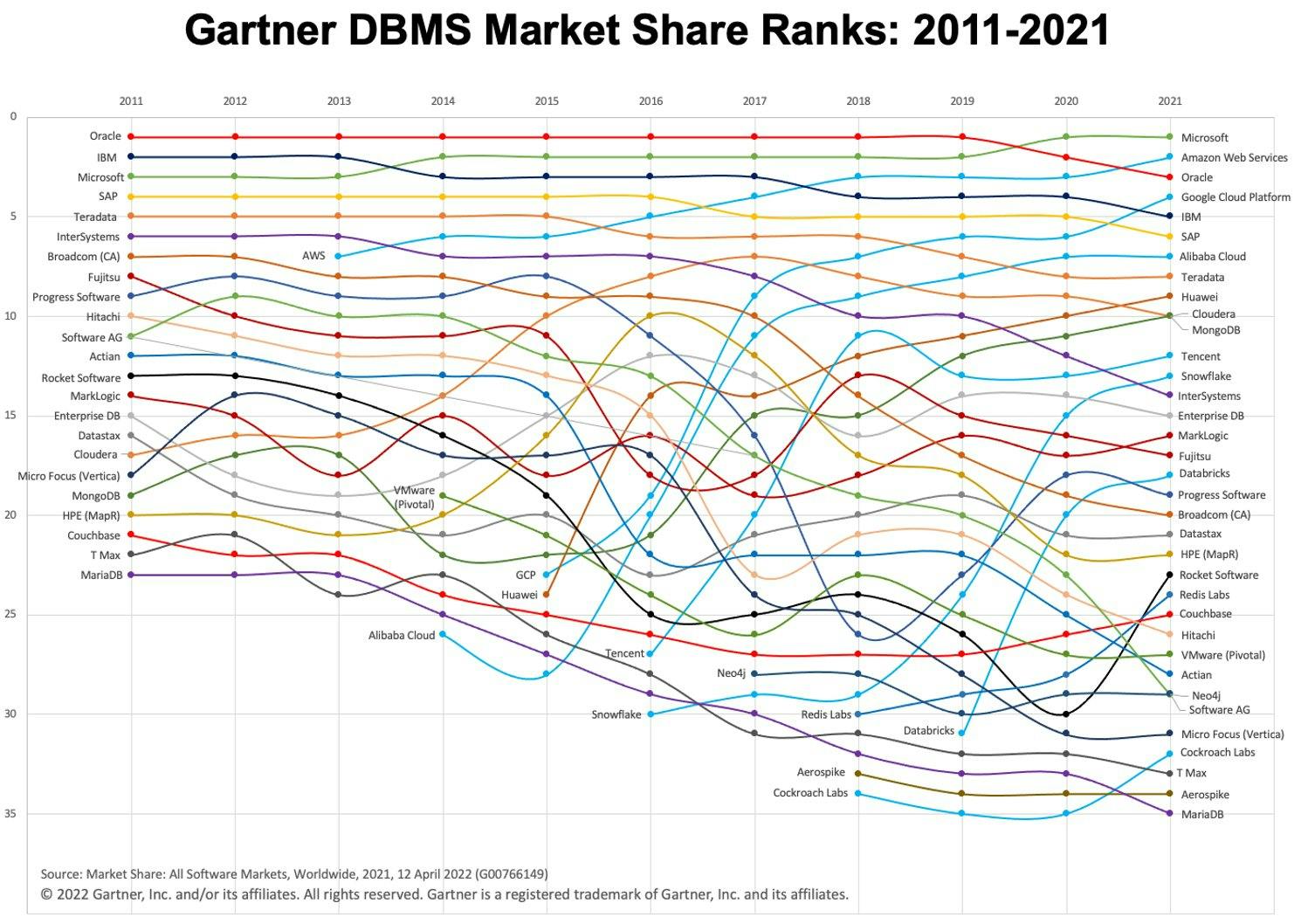 Image: Gartner via Adam Ronthal (@aronthal) on Twitter.
Image: Gartner via Adam Ronthal (@aronthal) on Twitter.
BigQuery, standing at #4 as of 2021, is a fully-managed, serverless data warehouse service offered by Google Cloud Platform (GCP). It enables easy and scalable analysis over petabytes of data and has long been known for its ease of use and maintenance-free nature.
Snowflake, is a similar service offered by the company Snowflake Inc. One of the principal differences is that Snowflake allows you to host the instance in either Amazon Web Services (AWS), Azure (Microsoft) or GCP (Google). This is a great advantage if you are already established in a non-GCP environment.
Exporting and Loading the data
As circumstances have it, it is sometimes necessary or desired to copy data from a BigQuery environment into a Snowflake environment. Let's take a look and break down the various logical steps needed to properly move this data around since neither competing services have an integrated function to easily do this. For the sake of our example, we will assume that our destination Snowflake environment is hosted on AWS.
Step By Step Procedure
In order to migrate data from BigQuery to Snowflake (AWS), these are the essential steps:
- Identify table or query and execute
EXPORT DATA OPTIONSquery to export to Google Cloud Storage (GCS). - Run script in VM or local machine to copy GCS data to Snowflake's Internal Stage. We could also read straight from GCS with a storage integration, but this involves another layer of secure access configuration (which may be preferable for your use case).
- Manually generate
CREATE TABLEDDL with correct column data types and execute in Snowflake. - Execute a
COPYquery in Snowflake to import staged files. - Optionally clean up (delete) temporary data in GCP and Internal Stage.
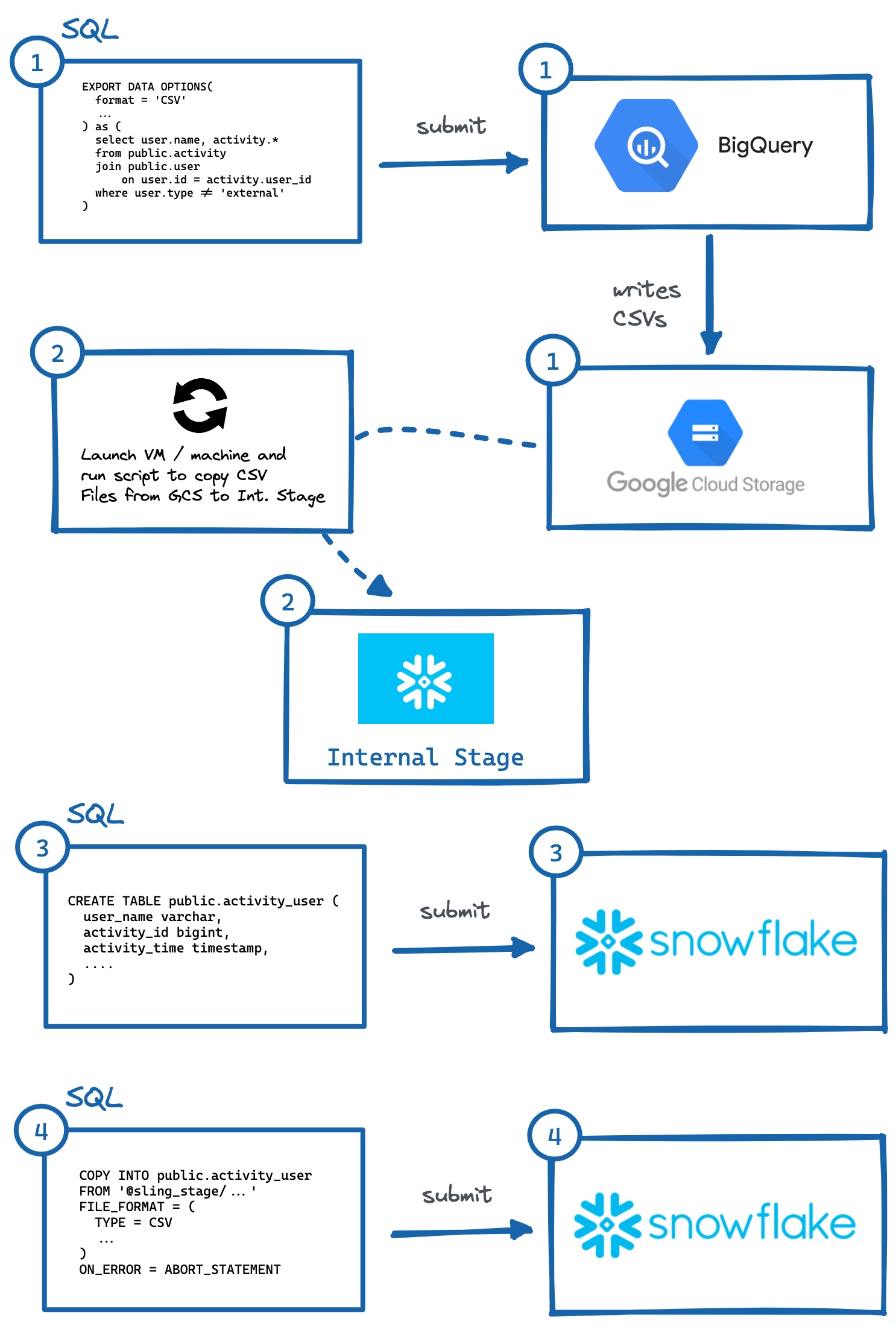 Image: Steps to manually export from BigQuery to Snowflake.
Image: Steps to manually export from BigQuery to Snowflake.
As demonstrated above, there are several steps to make this happen, where independent systems need to be interacted with. This can be cumbersome to automate, especially generating the correct DDL (#3) with the proper column types in the destination system (which I personally find the most burdensome, try doing this for tables with 50+ columns).
Fortunately, there is an easier way to do this, and it is by using a nifty tool called Sling. Sling is a data integration tool which allows easy and efficient movement of data (Extract & Load) from/to Databases and Storage Platforms. There are two ways of using it: Sling CLI & Sling Cloud. We will do the same procedure as above, but only by providing inputs to sling and it will automatically do the intricate steps for us!
Using Sling CLI
If you are a fanatic of the command line, Sling CLI is for you. It is built in go (which makes it super-fast), and it works with files and databases. It can also work with Unix Pipes (reads standard-input and writes to standard out). We can quickly install it from our shell:
# On Mac
brew install slingdata-io/sling/sling
# On Windows Powershell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Using Python Wrapper via pip
pip install sling
Please see here for other installation options (including Linux). There is also a Python wrapper library, which is useful if you prefer interacting with Sling inside of Python.
Once installed, we should be able to run the sling command, which should give us this output:
sling - An Extract-Load tool | https://slingdata.io
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Now there are many ways to configure tasks, but for our scope in this article, we first need to add connections credentials for BigQuery and Snowflake (a one time chore). We can do this by opening the file ~/.sling/env.yaml, and adding the credentials, which should look like this:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: publicGreat, now let's test our connections:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Fantastic, now that we have our connections setup, we can run our task:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
Wow, that was easy! Sling did all the steps that we described prior automatically. We can even export the Snowflake data back to our shell sdtout (in CSV format) by providing just the table identifier (public.activity_user) for the --src-stream flag and count the lines to validate our data:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Conclusion
We are in an era where data is gold, and moving data from one platform to another shouldn't be difficult. As we have demonstrated, Sling offers a powerful alternative by reducing friction associated with data integration. We'll be covering how to export from Snowflake and loading into BigQuery in another post.