Introduction
Sling is an easy-to-use, lightweight data loading tool, typically run from the CLI. It focuses on data movement between Database to Database, File System to Database and Database to File System. See here for the list of Connectors.
Today, we're going to be looking at parsing a complex JSON file (a dbt manifest file), extracting a sub-set of data and writing it into a CSV file for further analysis.
JMESPath
JMESPath is the most popular query / transformation language for JSON. It has many libraries ready to use, including Go, which is what Sling is built with. Some key features of JMESPath:
Filtering and Projection: You can use JMESPath expressions to filter and project specific elements or attributes from JSON data. This allows you to focus on the relevant parts of a JSON structure.
Functions: JMESPath includes a set of built-in functions that can be used in expressions for various tasks, such as string manipulation, mathematical operations, and more. These functions enhance the flexibility of JMESPath queries.
Multi-level Queries: JMESPath supports querying JSON documents with nested structures. You can navigate through arrays and objects to access the data at different levels within the JSON hierarchy.
Pipes and Operators: JMESPath expressions can include pipes (|) and various operators for combining and transforming data. This allows you to create more complex queries and transformations.
Running Sling
Let us assume we are working from our dbt project folder, and that we have run the dbt compile command. This would have generated a target folder, containing the beefy manifest.json file. We will be extracting the models dataset from that file.
After installing sling, we are good to go. From the root of our dbt project (folder containing the dbt_project.yaml), run the following command:
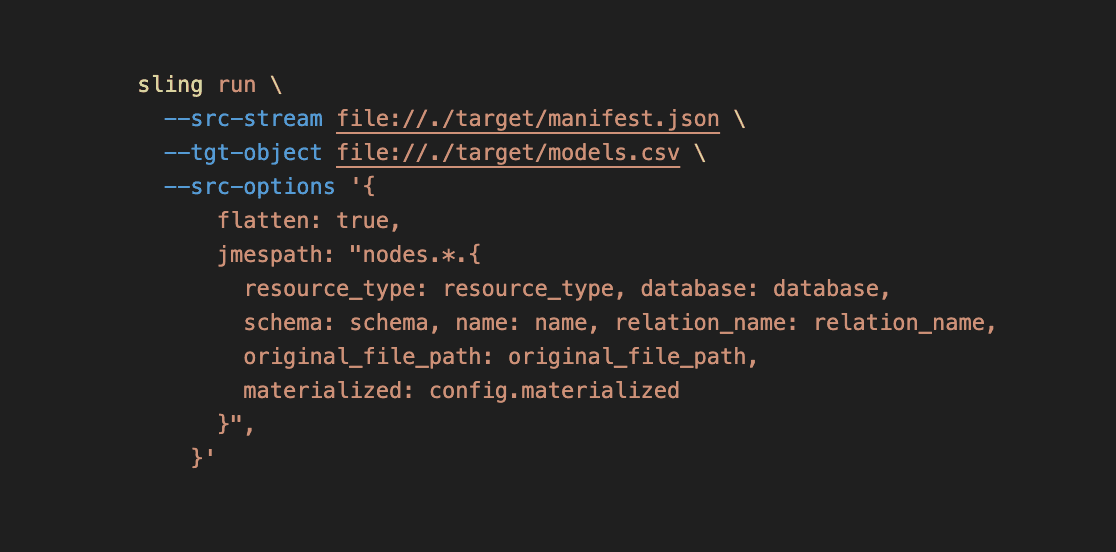
sling run \
--src-stream file://./target/manifest.json \
--tgt-object file://./target/models.csv \
--src-options '{
flatten: true,
jmespath: "nodes.*.{resource_type: resource_type, database: database, schema: schema, name: name, relation_name: relation_name, original_file_path: original_file_path, materialized: config.materialized }",
}'
Let's go over the inputs we provided:
--src-stream: this is the source stream that we want to read from, which is the dbt manifest file in the target folder.
--tgt-object: this is the destination file path that we want to write to. Here we are writing to a CSV file, but Sling can write to JSON and Parquet as well. We'd just need to just change the extension to .json or .parquet.
--src-options: Here, we specify the source options for Sling to use.
Let's take a look at the output.
6:34AM INF reading from source file system (file)
6:34AM INF writing to target file system (file)
6:34AM INF wrote 41 rows to file://./target/models.csv [1,432 r/s]
6:34AM INF execution succeeded
Great! Your data is ready for further analysis. Let look at a sample of the output CSV file:
$ head ./target/models.csv
database,materialized,name,original_file_path,relation_name,resource_type,schema
MY_DATABASE,incremental,track_events_raw,models/track_events_raw.sql,MY_DATABASE.dbt_dev.track_events_raw,model,dbt_dev
MY_DATABASE,test,test_mapping_global_graph_uuid,tests/test_mapping_global_graph_uuid.sql,,test,dev_dbt_test__audit
MY_DATABASE,incremental,track_events,models/track_events.sql,MY_DATABASE.dbt_dev.track_events,model,dbt_dev
MY_DATABASE,table,mapping_invalid_shopify,models/mapping/mapping_invalid_shopify.sql,MY_DATABASE.dbt_dev.mapping_invalid_shopify,model,dbt_dev
MY_DATABASE,table,mapping_global,models/mapping/mapping_global.sql,MY_DATABASE.dbt_dev.mapping_global,model,dbt_dev
MY_DATABASE,test,not_null_edges_edge_b,models/schema.yml,,test,dev_dbt_test__audit
MY_DATABASE,test,unique_id_graph_edge,models/schema.yml,,test,dev_dbt_test__audit
MY_DATABASE,table,mapping_invalid_anonymous,models/mapping/mapping_invalid_anonymous.sql,MY_DATABASE.dbt_dev.mapping_invalid_anonymous,model,dbt_dev
MY_DATABASE,test,test_mapping_global_graph_unique,tests/test_mapping_global_graph_unique.sql,,test,dev_dbt_test__audit
Neat! In seconds, we were able to create a perfect CSV file, with the columns that we want from the JSON nested nodes. And that's not it, sling can readily load this into a target database as well. See the docs for more examples!